Simple Kubernetes deployment
I am a software developer who is passionate about creating innovative and efficient solutions to complex problems. I also enjoy writing about my personal projects and sharing my knowledge with others. I am maintaining a blog to document my coding adventures, share tips and tricks for software development, and discuss interesting topics in computer science.
Prerequisites:
have a running Kubernetes cluster. Check out here to create one yourself
have a copy of our backend server code and image. Check out here to create
We will deploy 1 backend-server image, 1 MongoDB image, 1 Redis image, and 1 InfluxDB image to our Kubernetes cluster.
Writing our Yaml files
Let's first set our 3 databases.
Mongo
# mongo.yaml apiVersion: apps/v1 kind: Deployment metadata: name: mongo-deployment spec: replicas: 1 selector: matchLabels: app: mongo template: metadata: labels: app: mongo spec: containers: - name: mongo image: mongo:4.4.18 resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 27017 ---Let's go through what we had written.
apiVersionis specified asapps/v1, this is the API version of the Kubernetes object being deployedkindisDeploymentmetadata.nameismongo-deployment. This is the name of our deployment. Metadata can contain descriptions of our deploymentsspecdescribes the state of our deployment.replicassets how many instances of pods we should be running, sets to1hereselector.matchLabelsspecifies which pods will be managed by the deployment based on the labels. This value here must match the pod label that we will be creating. Here we set to match the labelmongotemplatedefines the pod used by the deployment to create new podsmetadata.labelsis used to label our pod, which we had labeled asmongo, this will be referenced by our deployment and service resourcespecspecify details of our containers, such as thename,image,resourcesandportsnamespecifies the name of our containerportsspecifies the ports that the container exposeswe want to expose
27017to other services so we define ports as such:ports: - containerPort: 27017resourcesspecifies the requests and limits for the container. we want to limit the CPU and memory of our container, as such we define our resources as such:resources: limits: memory: "128Mi" cpu: "500m"imagespecifies the docker image to use for the containerWe will be using the docker image from the docker hub and the image can be defined as <image_name>:<tag>, we are using version 4.4.18 here. (Mongo version 5+ might not run on Kubernetes so we are using an older version, check out this issue)
Next, we can define the service spec
# mongo.yaml
# deployment written earlier
---
apiVersion: v1
kind: Service
metadata:
name: mongo-service
spec:
selector:
app: mongo
ports:
- protocol: TCP
port: 27017
targetPort: 27017
Let's go through what we had written.
apiVersionspecifies the API version for the servicekindis aService, a Service is a Kubernetes resource that allows a way for pods to be accessed.metadata.namespecifies the name of our service asmongo-servicespecdescribes the state of our serviceselectorspecifies the set of pods that follow this service configuration, mainly through the labels. We set this value to be the same label set earlier,mongoportsspecifies the ports exposed by the serviceprotocolis the network protocol used, we usetcphereportis the port number we want to be exposed to,27017targetPortspecifies the port on the pod targeted by the serviceThe service maintains its range of ports used (port) and this is mapped to the port used on the pod (targetPort)
Redis
This is similar to Mongo deployment, the only difference is Redis port we will use
6379# redis.yaml apiVersion: apps/v1 kind: Deployment metadata: name: redis-deployment spec: replicas: 1 selector: matchLabels: app: redis template: metadata: labels: app: redis spec: containers: - name: redis image: redis:alpine resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 6379 --- apiVersion: v1 kind: Service metadata: name: redis-service spec: selector: app: redis ports: - protocol: TCP port: 6379 targetPort: 6379InfluxDB
For InfluxDB, other than changing the port to
8086, it also has a few environmental variables that need to be set for the containers. InfluxDB also exposes a web UI that we can access so we will need to expose this to the network outside our Kubernetes.apiVersion: apps/v1 kind: Deployment metadata: name: influx-deployment spec: replicas: 1 selector: matchLabels: app: influx template: metadata: labels: app: influx spec: containers: - name: influx image: influxdb:alpine resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 8086 env: - name: DOCKER_INFLUXDB_INIT_MODE value: "setup" - name: DOCKER_INFLUXDB_INIT_USERNAME value: "andre" - name: DOCKER_INFLUXDB_INIT_PASSWORD value: "12345678" - name: DOCKER_INFLUXDB_INIT_ORG value: "andre" - name: DOCKER_INFLUXDB_INIT_BUCKET value: "bucket1" - name: DOCKER_INFLUXDB_INIT_ADMIN_TOKEN value: "my-token" --- apiVersion: v1 kind: Service metadata: name: influx-service spec: type: NodePort selector: app: influx ports: - protocol: TCP port: 8086 targetPort: 8086 nodePort: 32000Explanations:
spec.template.spec.envspecifies our environmental variables for the containers. We have written a few that are required by the InfluxDB image, for example, the password and the admin token. We will take this out later and put it under Secrets.spec.typeunder Service is set toNodePort.NodePorthere specifies the port number allocated on every node of the cluster. This is used to access the service externally, mainly to access our web UI
API server
Now we can write our deployment for api-server. We will be using port
8080for our container and port80for our service. This maps port80of the service to port8080of the container.We also declared the
ENVandNAMESPACEenvironmental variables for this container to be used in our code later.Our image for the api-server is using the one we had previously uploaded to the docker hub,
andrewongzh/api-server:1.0.0. This is in the format of <username>/<repo_name>:<tag_name># api-server.yaml apiVersion: v1 kind: Service metadata: name: api-server-service spec: type: NodePort selector: app: api-server ports: - protocol: TCP port: 80 targetPort: 8080 # the port number which the service will forward to nodePort: 32001 # this port is exposed externally outside of k8s --- apiVersion: apps/v1 kind: Deployment metadata: name: api-server-deployment annotations: description: "this is my normal backend server deployment" version: "1.0" spec: replicas: 1 selector: matchLabels: app: api-server template: metadata: labels: app: api-server spec: containers: - name: api-server-container image: andrewongzh/api-server:1.0.1 # update the link to image registary resources: # declare resources limits and request limits: memory: "512Mi" cpu: "1" requests: memory: "256Mi" cpu: "0.2" ports: # container ports exposed - containerPort: 8080 env: - name: TEST value: "1-2-3" - name: ENV value: "k8" - name: NAMESPACE value: "homek8" - name: DOCKER_INFLUXDB_INIT_ADMIN_TOKEN value: "my-token"
Updating API-server code
Using the same ENV key we defined before, we can add an if else statement to check ENV == "k8" for Kubernetes deployment. If so, we can then change the URI of our client DB connection and replace it with the format of <URI_scheme>://<service-name>.<namespace>.svc.cluster.local:<port>. service-name is what we defined in our Service yaml earlier, which will resolve to the IP address via internal DNS resolution. namespace is the namespace we decided to deploy on which is homek8.
var ENV = os.Getenv("ENV")
var nameSpace = os.Getenv("NAMESPACE")
func MongoClientInit() *mongo.Client {
defer cancel()
address := "mongodb://localhost:27017"
if ENV == "dockercompose" {
address = "mongodb://mongo:27017"
} else if ENV == "k8" {
// hard coded service name here
address = fmt.Sprintf("mongodb://mongo-service.%s.svc.cluster.local:27017", nameSpace)
}
mongoClient, err := mongo.Connect(ctx, options.Client().ApplyURI(address))
if err != nil {
panic(err)
}
if err := mongoClient.Ping(ctx, nil); err != nil {
panic(err)
}
fmt.Println("Connect to mongodb OK")
return mongoClient
}
func RedisClientInit() *redis.Client {
address := "localhost:6379"
if ENV == "dockercompose" {
address = "redis:6379"
} else if ENV == "k8" {
// hard coded service name here
address = fmt.Sprintf("redis-service.%s.svc.cluster.local:6379", nameSpace)
}
rdb := redis.NewClient(&redis.Options{
Addr: address,
Password: "",
DB: 0,
})
if err := rdb.Ping(redisCtx); err.Err() != nil {
panic(err)
}
fmt.Println("Connect to redis OK")
return rdb
}
func InfluxClientInit() *influxdb2.Client {
address := "http://localhost:8086"
if ENV == "dockercompose" {
address = "http://influx:8086"
} else if ENV == "k8" {
// hard coded service name here
address = fmt.Sprintf("http://influx-service.%s.svc.cluster.local:8086", nameSpace)
}
ifxdb := influxdb2.NewClient(address, influxToken)
ok, err := ifxdb.Ping(influxCtx)
if err != nil {
panic(err)
}
if !ok {
panic("Unable to connect to influxdb")
}
fmt.Println("Connect to influx OK")
return &ifxdb
}
Let's rebuild the image and push it to docker hub tagged as 1.0.1
docker build . -t andrewongzh/api-server:1.0.1
docker push andrewongzh/api-server:1.0.1
Deploying to Kubernetes
We will ssh into our machine and use the kubectl command to execute our deployments.
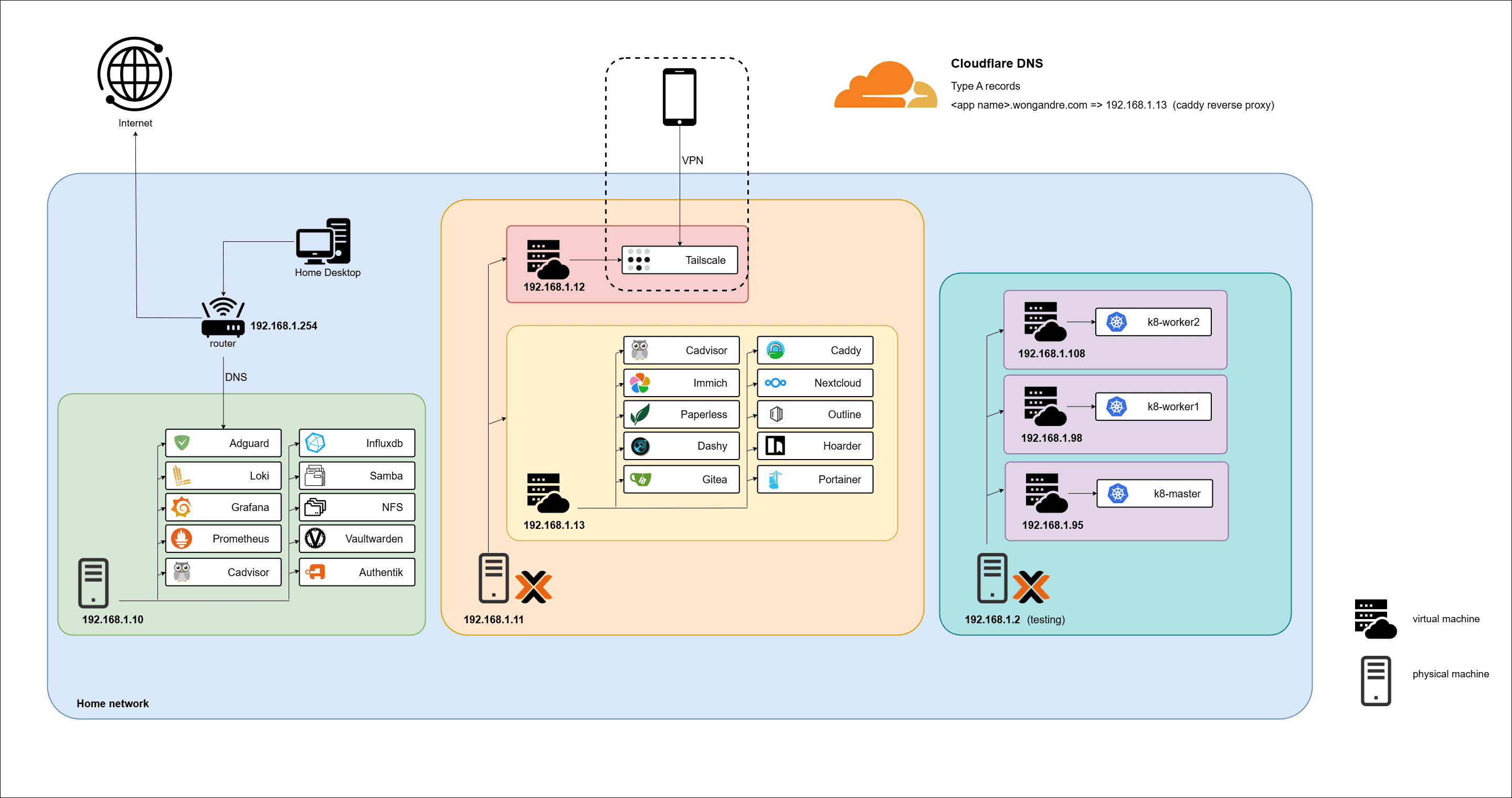
First, we can create a namespace called homek8 for this deployment. A namespace allows us to separate our deployments from the rest of the deployments in Kubernetes clusters. This is useful if we want to isolate resources via different users or projects.
kubectl create namespace homek8
Next, we can start deploying
# -f referes to the yaml file we want to use
kubectl apply -f influx.yaml --namespace=homek8
kubectl apply -f mongo.yaml -n homek8
kubectl apply -f redis.yaml -n homek8
kubectl apply -f api-server.yaml -n homek8
We can verify if our deployments are successful
kubectl get pods -n homek8
# output
NAME READY STATUS RESTARTS AGE
influx-deployment-5c875ffdbc-rmh9w 1/1 Running 0 28s
mongo-deployment-67b6bbf7fd-66thz 1/1 Running 0 10s
redis-deployment-f76b8d78c-n7r4d 1/1 Running 0 5s
When we create a deployment, it creates a replica set and names it as <deployment_name>-<random-string>. In the case of our influxDB deployment, the replica set name is influx-deployment-5c875ffdbc. The replica set then creates the pods which will add another random string to the back which is rmh9w.
We can also try to access our influxDB web UI via http://192.168.1.95:32000/, where the IP is any of our nodes and the port is previously defined under nodePort , which is 32000.
To test our API server, we can make a simple curl command to it
curl http://192.168.1.95:32001
# output
{"hello":"world"}
Let's change our current context to always use the home8 namespace so we don't have to keep typing it
kubectl config set-context --current --namespace=homek8
Let's look at our api-server's log, we can either dump out the logs or stream it
# get logs via pod name
# -f to stream the logs
kubectl logs -f api-server-deployment-77fb9b8bcc-sx6c8
# get logs via deployment name
kubectl logs deploy/api-server-deployment
Let's increase the number of replicas for our api-server to 2 then apply our yaml file again.
kubectl apply -f api-server.yaml
kubectl get pods
# now we get 2 pod names
api-server-deployment-77fb9b8bcc-sx6c8 1/1 Running 0 16m
api-server-deployment-77fb9b8bcc-xnbnc 1/1 Running 0 104s
If we want to delete our deployments, we can use kubectl delete
kubectl delete -f influx.yaml
kubectl delete -f mongo.yaml
kubectl delete -f redis.yaml
Managing environmental variables
Let's move the environmental variables into ConfigMap and Secret.
# config-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: homek8-configmap
data:
TEST: "1-2-3"
ENV: "k8"
NAMESPACE: "homek8"
DOCKER_INFLUXDB_INIT_MODE: "setup"
DOCKER_INFLUXDB_INIT_USERNAME: "andre"
DOCKER_INFLUXDB_INIT_ORG: "andre"
DOCKER_INFLUXDB_INIT_BUCKET: "bucket1"
We can convert our password into baseb4 encoded required in the secret.yaml via echo -n "12345678" | baseb4
# secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: homek8-secret
type: Opaque
data:
DOCKER_INFLUXDB_INIT_ADMIN_TOKEN: bXktdG9rZW4= # base64 encoded of my-token
DOCKER_INFLUXDB_INIT_PASSWORD: MTIzNDU2Nzg= # base64 encoded of 12345678
In our deployment, we can reference it in 2 different ways:
Use envFrom to reference the name of our configMap or secret via configMapRef and secretRef and reference our name homek8-configmap and homek8-secret
The second way is to use valueFrom.secretKeyRef or valueFrom.configMapKeyRef to reference the name and key of our resources under env.
# influx.yaml
spec:
containers:
- name: influx
image: influxdb:alpine
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 8086
envFrom:
- configMapRef:
name: homek8-configmap
env:
- name: DOCKER_INFLUXDB_INIT_PASSWORD
valueFrom:
secretKeyRef:
name: homek8-secret
key: DOCKER_INFLUXDB_INIT_PASSWORD
- name: DOCKER_INFLUXDB_INIT_ADMIN_TOKEN
valueFrom:
secretKeyRef:
name: homek8-secret
key: DOCKER_INFLUXDB_INIT_ADMIN_TOKEN
# api-server.yaml
envFrom:
- configMapRef:
name: homek8-configmap
- secretRef:
name: homek8-secret
Manage volumes for our databases
We can add persistent volume for our instances so that our data will not disappear if the database instances have crashed.
We can create our Persistent Volume for our claims later.
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongo-pv
labels:
name: mongo-pv
spec:
capacity:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /mongo
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: influx-pv
labels:
name: influx-pv
spec:
capacity:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /influx
---
metadata.labels specifies the label on our PV, which will be referenced by the PVC later.
accessModes specifies how many pods can access and how many nodes can mount this volume
resources.requests.storage specifies the size of the storage we require
hostPath specifies the location of where this storage mounts a folder on the node's filesystem (not recommended by k8 but an easy way for testing)
We can create a Persistent Volume Claim for each of our DB which is a storage request.
# pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongo-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
selector:
matchLabels:
name: mongo-pv
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: influx-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
selector:
matchLabels:
name: influx-pv
---
metadata.name here can be referenced later in our deployment
accessModes specifies how many pods can access and how many nodes can mount this volume
resources.requests.storage specifies the size of the storage we require
selector.matchLabels specifies the persistent volume to bind to
We can then apply this to our Kubernetes cluster: kubectl apply -f pvc.yaml -f pv.yaml and we can view their status as below
kubectl get pvc
# output
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
influx-pvc Bound influx-pv 1Gi RWO 6m54s
mongo-pvc Bound mongo-pv 1Gi RWO 6m54s
kubectl get pv
# output
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
influx-pv 1Gi RWO Retain Bound homek8/influx-pvc 6m52s
mongo-pv 1Gi RWO Retain Bound homek8/mongo-pvc 6m52s
Now we can update our DB deployments to include volumes:
# mongo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongo-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
spec:
containers:
- name: mongo
image: mongo:4.4.18
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 27017
volumeMounts:
- name: mongo-storage # name of the volume
mountPath: /data/db
volumes:
- name: mongo-storage
persistentVolumeClaim:
claimName: mongo-pvc
---
For Mongo, we are mounting it to /data/db
For InfluxDB, we are mounting it to /var/lib/influxdb
Conclusion
We learned how to create deployment yaml files and deploy them to our Kubernetes clusters. We used a few Kubernetes api-resources such as Deployment, Service, ConfigMap, Secret, PersistentVolume, and PersistentVolumeClaims.